Tridi: Trilateral diffusion of 3d humans, objects, and interactions
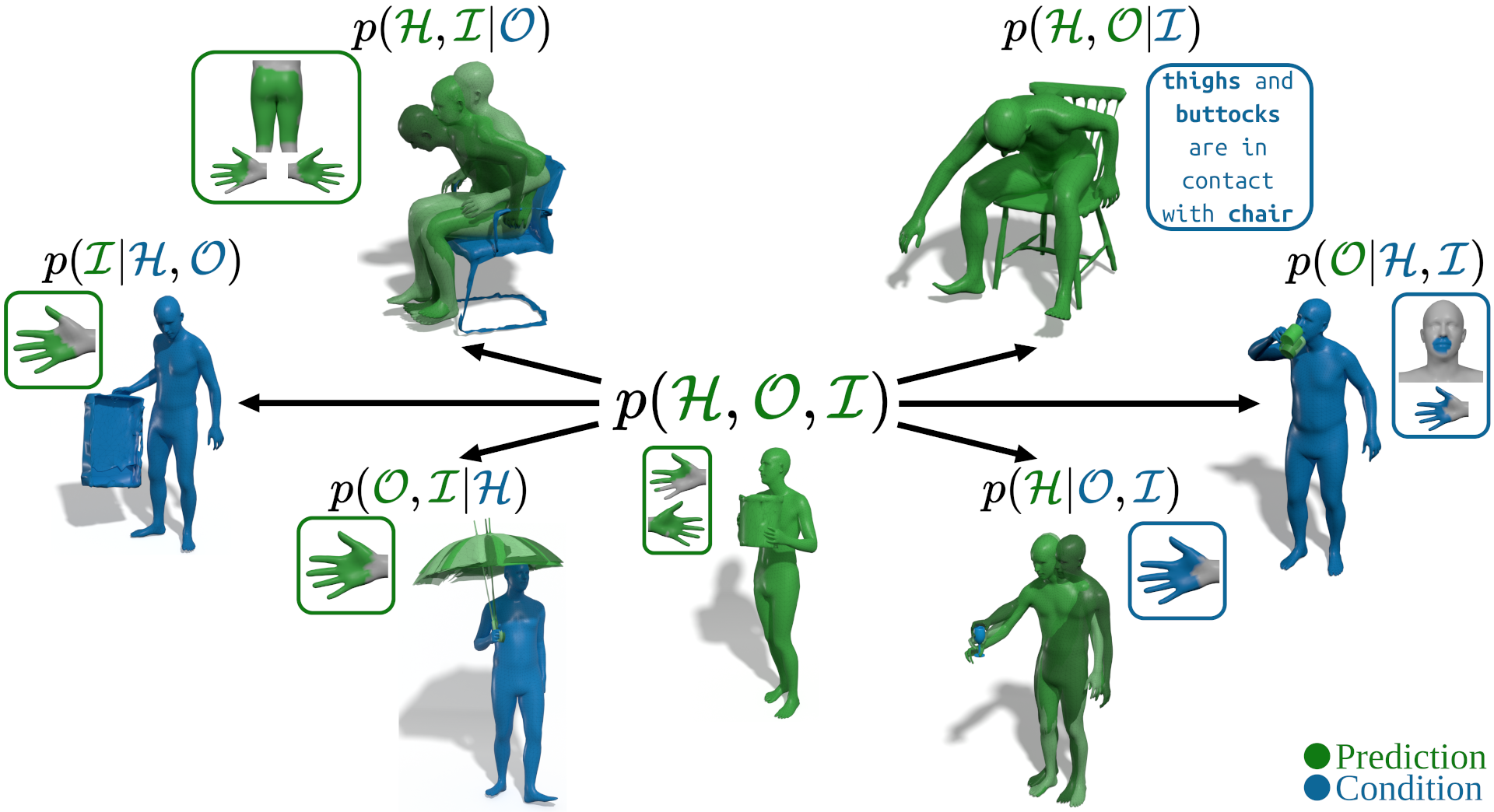
A unified framework for generative 3D Human-Object Interaction, capable of operating in seven different modes. Built on top of the Unidiffuser formulation, our method is trained to process different combinations of input and infer the unobserved ones as a conditional denoising approach. Our method is general, covering the use cases of all previous works. At the same time, it outperforms networks specialized in individual tasks, demonstrating the benefit of a more comprehensive formulation of Human-Object Interaction.